예외 기본 내용 복습 + 실무에 필요한 체크/언체크 예외 차이점과 활용 방안에 대한 내용이다.
예외 계층
체크 예외와 언체크 예외가 어떤 구조로 되어있는지는 다음과 같다.
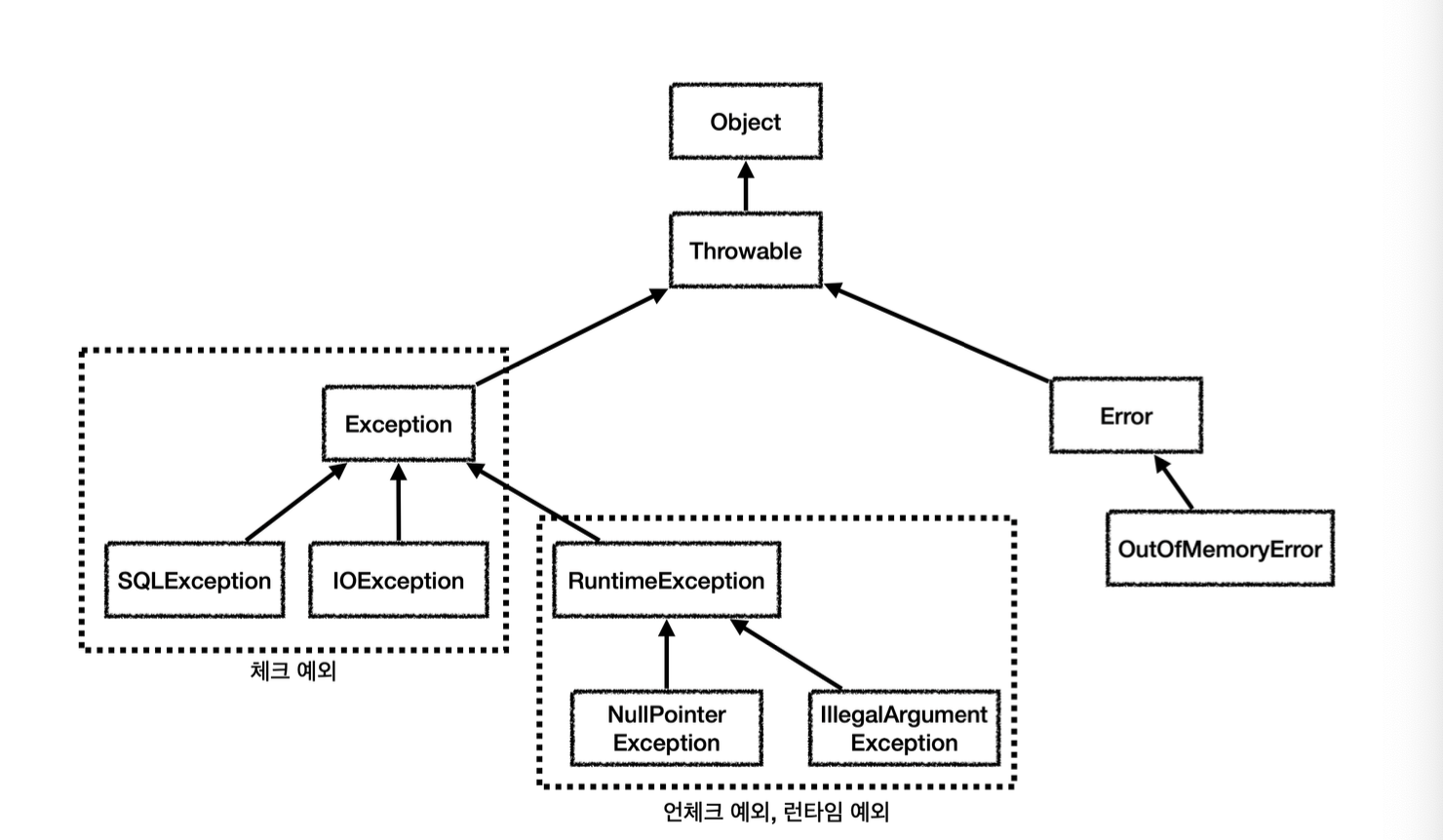
- Object : 예외도 객체이기에 모든 예외의 최상위 부모는 Object이다.
- Throwable : 최상위 예외이다. 하위에 Exception과 Error가 있다.
- Error : 언체크 예외
- 애플리케이션에서 복구 불가능한 시스템 예외이다. 메모리 부족 or 심각한 시스템 오류가 해당된다. 이 에러는 개발자 잡으려 해서는 안된다.
- 상위 예외를 catch로 잡으면 그 하위 예외까지 함께 잡는다. 따라서 애플리케이션 로직에서는 Throwable 예외도 잡으면 안되는데 이유는 Error 예외도 함께 잡을 수 있기 때문이다.
- 따라서 애플리케이션 로직은 Exception부터 예외로 생각하고 잡으면 된다.
- Exception : 체크 예외
- 애플리케이션 로직에서 사용할 수 있는 실질적인 최상위 예외이다.
- Exception을 포함한 하위 예외는 모두 체크 예외이다. 체크 예외는 모두 컴파일러가 체크한다.
- RuntimeException은 체크 예외가 아닌 언체크 예외이다.
- RuntimeException : 언체크 예외, 런타임 예외
- 언체크 예외로, 이는 컴파일러가 체크하지 않는 언체크 예외이다.
- RuntimeException과 그 하위 예외가 해당된다.
- 주로 런타임 예외 = 언체크 예외로 부른다.
예외 기본 규칙
예외는 폭탄 돌리기와 같다. 잡아서 처리하거나(예외 처리) 처리할 수 없으면 밖으로 던져야 한다(예외 던짐).
예외처리
예외처리는 예외를 잡아서 처리하는 것으로, 예외 처리 후에는 애플리케이션 로직이 정상 흐름으로 동작한다.

예외 던짐
예외를 처리하지 못하면 호출한 곳으로 예외를 계속 던진다. 불이 꺼지지 않고 계속 옮겨지는 것과 같다.

- 만약 예외를 처리하지 못하고 계속 던지면 어떻게 될까?
- 자바 main() 스레드의 경우, 예외 로그를 출력하면서 서버가 죽는다.
- 웹 애플리케이션의 경우 여러 사용자 요청을 처리하기 때문에 하나의 예외 때문에 서버가 죽으면 안된다. WAS가 해당 예외를 받아서 처리하는데, 주로 개발자가 지정한 오류페이지를 사용자에게 보여준다.
체크 예외 vs. 언체크 예외
- 체크 예외 : 예외를 잡아서 처리하지 않으면 항상 [throws 예외]를 선언해야 한다.
- 언체크 예외 : 예외를 잡아서 처리하지 않아도 throws를 생략할 수 있다.
→ 예외를 처리할 수 없을 때 예외를 밖으로 던지는 부분이 차이다.
체크 예외
RuntimeException을 제외한 Exception과 하위 예외는 모두 컴파일러가 체크하는 체크 예외이다.
체크 예외는 잡아서 처리하거나, 또는 밖으로 던지도록 선언해야 한다. 그렇지 않으면 컴파일 오류가 발생한다.
Exception을 상속받은 예외는 체크 예외가 된다.
static class MyCheckedException extends Exception {
public MyCheckedException(String message) {
super(message);
}
}- MyCheckedException은 Exception을 상속받았으므로 체크 예외가 되었다.
- 참고로 RuntimeException도 Exception을 상속 받지만 언체크 예외이다. 이는 자바 언어에서 문법으로 정한 것이다.
체크 예외를 잡아서 처리하는 코드
repository에서 call()을 호출한 뒤 MyCheckedException이 throw 되면 잡는 로직이다.
try {
repository.call();
} catch (MyCheckedException e) {
// 예외 처리 로직
}- catch는 해당 타입과 그 하위 타입을 모두 잡을 수 있다.
- catch (Exception e) 로 설정해도 MyCheckedException을 잡을 수 있다. 다만 Exception은 예외 최상위 클래스이기 때문에 다른 하위 예외까지 모두 잡힐 수 있기 때문에 권장하는 방식은 아니다.
체크 예외를 밖으로 던지는 코드
체크 예외를 처리할 수 없을 때는 method() throws 예외 를 사용해 밖으로 던질 예외를 필수로 지정해주어야 한다. 만약 체크 예외를 throws로 체크하지 않으면 컴파일 에러가 발생한다.
public void callThrow() throws MyCheckedException {
repository.call();
}→ 체크 예외는 예외를 잡아서 처리하거나 throws를 지정해 밖으로 예외를 던진다는 선언을 필수로 해야한다.
- 참고
public void callThrow() throws Exception {
repository.call();
}- throws는 지정한 타입과 그 하위 타입 예외를 밖으로 던진다.
- 예시로 throws Exception을 적어도 MyCheckedException을 던질 수 있다.
체크 예외 장단점
체크 예외는 예외를 잡아서 처리하거나 처리할 수 없는 경우 throws 예외를 통해 예외를 밖으로 던져야 한다. 그렇지 않으면 컴파일 에러가 발생하는데, 이로 인해 장단점이 존재한다.
- 장점
- 개발자가 실수로 예외를 누락하지 않도록 컴파일러를 통해 문제를 잡아주는 안전장치 역할을 한다.
- 단점
- 이때문에 개발자가 모든 체크 예외를 반드시 잡거나 던지도록 처리해야 하기 때문에 번거롭다.
- 현재 단계에서 처리할 수 없거나 신경쓰고 싶지 않은 예외까지 모두 챙겨서 처리하든지 던지든지 해야한다.
언체크 예외
언체크 예외는 RuntimeException를 포함한 하위 예외이다. 즉, RuntimeExeption을 extends한 예외를 의미한다.
언체크 예외는 말 그대로 컴파일러가 예외를 체크하지 않는다는 뜻이다.
언체크 예외는 체크 예외가 기본적으로 동일하다. 차이가 있다면 예외를 던지는 throws를 선언하지 않고, 생략할 수 있다. 이 경우 자동으로 예외를 던진다.
언체크 예외 처리하기
언체크 예외 처리는 잡아도 되고, 잡지 않고 던져된다. 언체크 예외를 던질 때는 method() throws 예외 를 명시하지 않아도 된다.
- 언체크 예외 잡아서 처리하기
try {
repository.call();
} catch (MyUncheckedException e) {
// 예외 처리 로직
log.info("error", e);
}
2. 언체크 예외를 밖으로 던지는 코드
// throws MyUncheckedException 생략
public void callThrow() {
repository.call();
}
// thrwos MyUncheckedException 선언
public void callThrow() throws MyUncheckedException {
repository.call();
}언체크 예외도 throws를 선언해도 되지만, 생략할 수도 있다.
언체크 예외 장단점
언체크 예외는 예외를 잡아서 처리할 수 없을 때, 예외를 밖으로 던지는 throws 예외를 생략할 수 있다. 이 때문에 장단점이 존재한다.
- 장점
- 신경 쓰고 싶지않은 언체크 예외를 무시할 수 있다. 그래서 신경 쓰고 싶지 않은 예외의 의존관계를 참조하지 않아도 된다.
- 단점
- 언체크 예외는 명시적 선언이 생략가능하기 때문에 개발자가 실수로 예외를 누락할 수 있다.
예외 활용
그럼 체크 예외와 언체크 예외는 언제 사용하면 좋을까?
다음 기본 원칙 2가지를 지키면 된다.
- 기본적으로 언체크 예외를 사용하자(요즘 트랜드는 런타임 예외만 주로 사용하는 것이다)
- 체크 예외는 비즈니스 로직상 의도적으로 던지는 예외만 사용하자
- 해당 예외를 잡아서 반드시 처리해야 하는 문제일 때만 체크 예외를 사용해야 한다.
- 예시) 계좌 이체 실패 예외, 결제시 포인트 부족 예외, 로그인 실패
체크 예외 문제점
체크 예외는 컴파일러가 예외 누락을 체크해주기 때문에 더 안전하고 좋아보이는데 왜 체크 예외를 기본으로 사용하는 것이 문제가 될까?

SQLException과 ConnectionException은 체크 예외인데 이 예외는 시스템 예외라 서비스, 컨트롤러에서 처리할 수 없다. 하지만 체크 예외이기 때문에 무조건 throws를 선언해야 한다.
이처럼 해결도 할 수 없는 문제를 계속 위로 던지는 것은 개발자 입장에서도 번거롭고, 사용자에게 에러를 알리기에도 모호하다(주로 “서비스에 문제가 있습니다.”라고 하는데 이는 사용자가 이해하기 어렵다).
정리하면 2가지 문제가 발생한다.
- 복구 불가능한 예외
- 대부분의 서비스나 컨트롤러에서 해결할 수 없는 문제이다.
- 그래서 해당 예외가 발생하면 로그를 남긱, 개발자가 해당 오류를 빠르게 인지할 수 있게 일관성 있게 공통 처리 하는 것이 필요하다.
- 의존 관계 문제
- 복구 불가능한 예외를 명시했기에 서비스와 컨트롤러는 의존하게 된다
- 이러면 나중에 기술이 변경되었을 때 해당 예외를 변경해야할 가능성이 높다. 이는 OCP를 어기게 되는 문제가 발생하게 된다.
- 코드 변경할 때마다 서비스 코드를 변경해야 하는 문제이다.
언체크 예외 활용

- Repository에서 SQLException을 RuntimeSQLException으로, ConnectionException을 RuntimeConnectException으로 변경했다.
- 이렇게 런타임 에외를 던지면 서비스와 컨트롤러에서 해당 예외를 선언하지 않고 던질 수 있다.
런타임 예외 구현 기술 변경시 파급 효과

- 따라서 중간에 기술이 변경되어도 해당 예외를 사용하지 않는 컨트롤러, 서비스에서는 코드를 변경하지 않아도 된다.
- 구현 기술이 변경되는 경우, 예외를 공통으로 처리하는 곳은 코드가 변경될 수 있다. 하지만 한 곳에서만 변경이 일어나기 때문에 변경 영향 범위가 최소화된다.
런타임 예외 문서화
런타임 예외는 문서화를 잘하거나 코드에 [throws 런타임 예외]를 남겨서 중요한 예외를 인지할 수 있게 해줘야 한다.
- 문서화 예시
/**
* Make an instance managed and persistent.
* @param entity entity instance
* @throws EntityExistsException if the entity already exists.
* @throws IllegalArgumentException if the instance is not an
* entity
* @throws TransactionRequiredException if there is no transaction when
* invoked on a container-managed entity manager of that is of type
* <code>PersistenceContextType.TRANSACTION</code>
*/
public void persist(Object entity);
예외 포함과 스택 트레이스
예외 전환 시 주의해야 할 것이 있다. 예외 전환시 기존 예외를 포함하는 것이다. 그렇지 않으면 스택 트레이스를 확인할 때 심각한 문제가 발생한다.
- 예외 전환 예시
public void call() {
try {
runSQL();
} catch (SQLException e) {
throw new RuntimeSQLException(e); //기존 예외(e) 포함
}
}
위 코드를 보면 체크 예외를 전환할 때 기존 예외인 SQLException 인스턴스 e를 파라미터로 넘긴다. 이렇게 해야 관련 에러가 발생했을 때 예외 추적이 가능하고, 그 원인이 SQLException이라는 것을 알 수 있다.
예외를 내가 직접 정해야 될 때 혹은 예외를 전활할 때는 꼭! 기존 예외를 포함하자.
Reference
인프런 김영한 - '스프링 DB 1편 - 데이터 접근 핵심 원리'
'Dev Language > Java' 카테고리의 다른 글
| [자바/JDBC] 스프링-DB 1편 1. JDBC의 이해 (0) | 2024.01.30 |
|---|---|
| [자바/기본] 12. 다형성과 설계 (0) | 2024.01.17 |
| [자바/기본] 11. 다형성2 (0) | 2024.01.17 |
| [자바/기본] 10. 다형성1 (0) | 2024.01.17 |
| [자바/기본] 9. 상속 (0) | 2024.01.16 |