로그 강의 수강 후 복습을 위해 작성하는 포스팅이며, 이전 포스팅은 여기에서 확인하실 수 있습니다.
5. Elasticsearch, Logstash로 로그 수집
5-1. 로그 수집

로그 수집이란, 여러 대의 애플리케이션 서버에서 발생한 로그들을 모아 중앙화된 저장소에 모으는 것을 의미한다.
1) 보통 서비스에서 생성된 로그들을 Logback을 통해 콘솔/파일/그 외 무언가로 로그를 기록한다.
2) Logback에 의해 생성된 산출물들을 Logstash를 이용해 Elasticsearch에 저장한다.
이 일련의 과정을 로그 수집이라고 한다.
그 다음 Kibana를 통해 Elastcisearch에 수집된 로그들을 시각화한 로그 상황을 확인할 수 있다.
5-2. 로그 수집이 필요한 이유
보통 작은 회사에서 여러 대의 서버를 돌리기 때문에,
1) 직접 각 서버에 접근해 로그를 수집하는 것은 번거롭기도 하고,
2) 데이터를 한데 모아서 관리하기가 어려워질 수 있다.
따라서 각 서버에서 발생한 로그 파일들을 한 곳에 모으는 것이 좋다.
본 강의에서는 각 로그 파일들을 ElasticSearch에 모으고, 그 모으는 걸 Logstash가 수행하는 프로세스를 학습했다.
5-3. ElasticSearch, Logstash 세팅하기
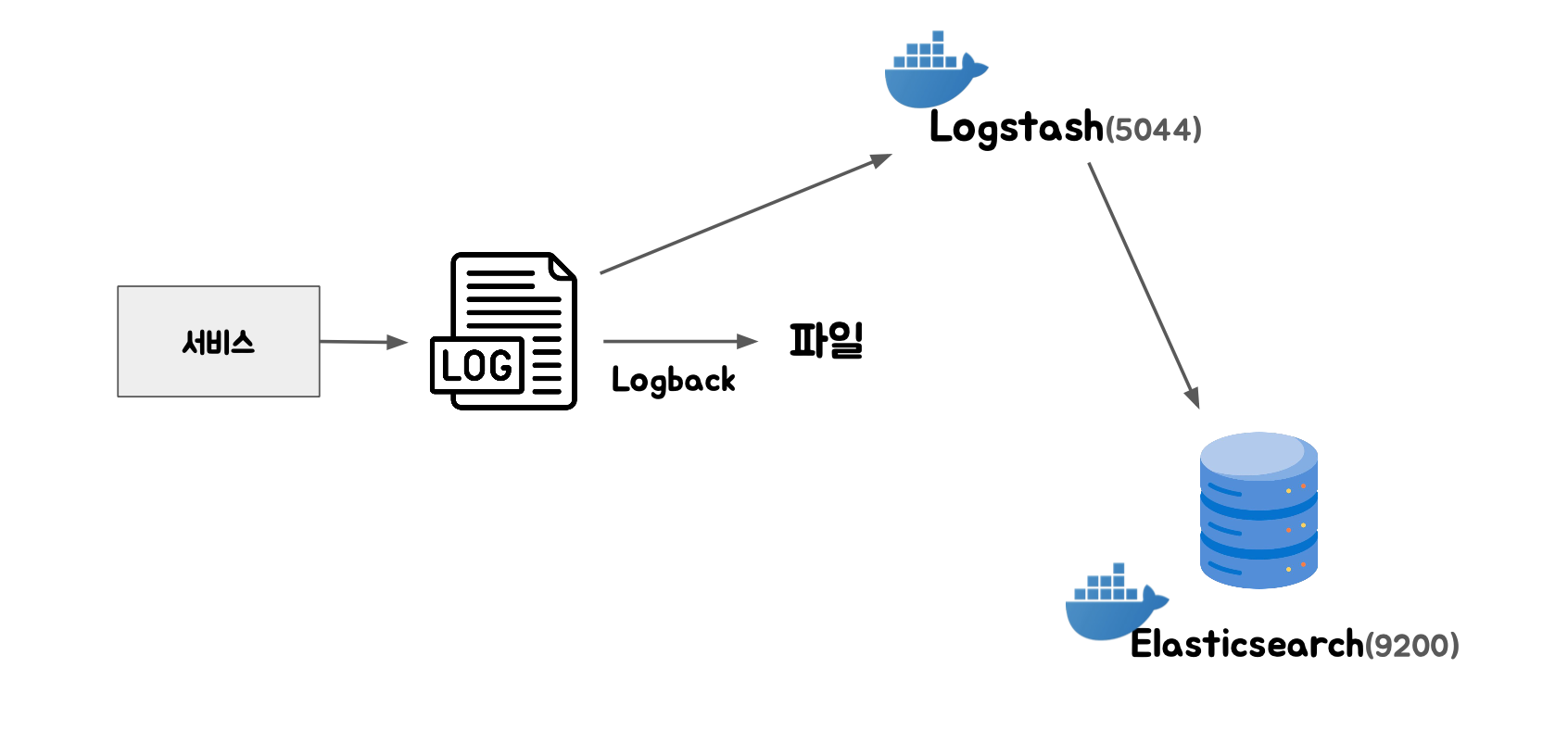
로그 수집을 위해 logstash, elastic search를 사용할건데, 이를 docker로 실행한다.
구체적인 과정은 다음과 같다.
1. docker를 다운로드 한 뒤, 실행시켜 아래 명령어를 IntelliJ 터미널에 입력해 docker를 실행한다.
docker run -d --name elasticsearch -p 9200:9200 -e "discovery.type=single-node" -e "xpack.security.enabled=false" -e "xpack.security.http.ssl.enabled=false" docker.elastic.co/elasticsearch/elasticsearch:8.10.0
2. pom.xml에 logstash 관련 의존성 추가한다.
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>7.4</version>
</dependency>
3. logback.xml 파일의 <appender> 설정도 변경해 logstash로도 log가 발송되도록한다.
<!-- Logstash로 전송할 Appender -->
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>localhost:5044</destination>
<encoder class="net.logstash.logback.encoder.LogstashEncoder" />
</appender>
4. logstash가 input으로 받은 로그를 elasticsearch로 output 되도록 구성한다.
./logstash.conf 파일을 생성한 뒤 아래 내용을 추가한다.
input {
tcp {
port => 5044
codec => json
}
}
output {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "application-logs-%{+YYYY.MM.dd}"
}
}
5. logstash, elasticsearch는 서로 다른 network에 있으므로 하나의 network로 묶어둔다.
docker network create elastic-network
docker network connect elastic-network elasticsearch
docker network connect elastic-network logstash
6. elasticsearch에서 어떤 index 목록이 있는지 확인한다.

7. kibana 명령어를 터미널에 실행 한 뒤 링크에 접속해 kibana로 로그 데이터를 시각화하는 대시보드를 만들 수도 있다.

docker run -d --name kibana --network elastic-network -p 5601:5601 -e "ELASTICSEARCH_HOSTS=http://elasticsearch:9200" kibana:8.10.1
본 내용은 주로 실습을 기반으로 진행되었기에 해당 내용은 참고만 하고, 실제로 Elasticsearch에 로그 파일이 쌓이는 것은 강의를 참고하시길 바랍니다.
6. 로그 레벨을 기준으로 알람 설정하기
WARN 로그 레벨인 경우에는 warn 로그가 n회 이상일 때 개발자에게 알림이 가게 설정해두는 정책이 있을 수 있다. 그럴 경우 스케줄러를 통해 알림을 발송 할 수 있다.
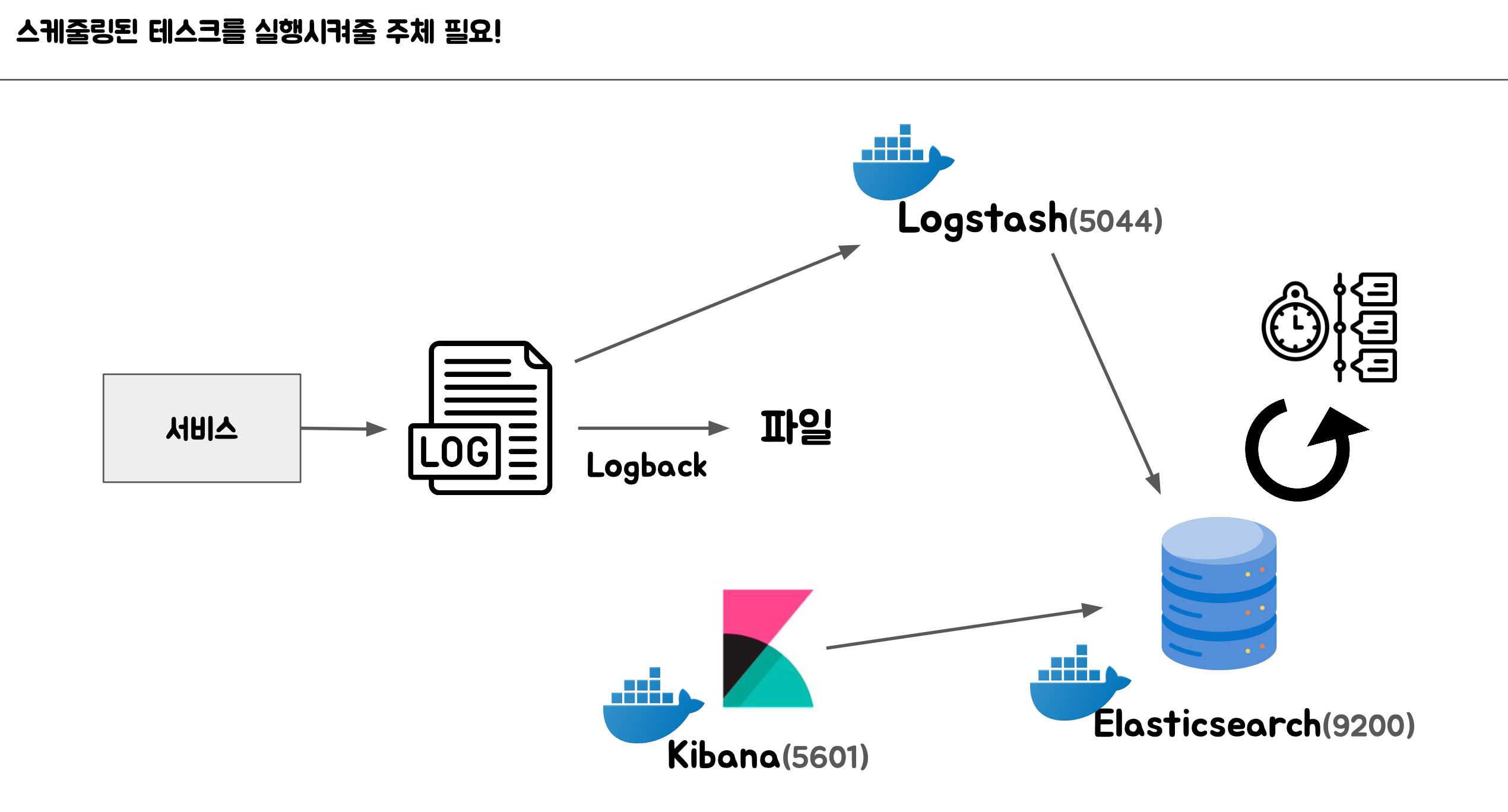
Elasticsearch 쿼리는 결국엔 단순한 HTTP 요청이고, 주기적으로 실행되는 태스크를 스케쥴링 태스크라고 한다.
- 스케쥴링 태스크 처리 솔루션
- 서버에 크론탭 등록 및 실행
- Jenkins 활용
- Kubernetes의 크론잡
- scdf
여기서 상황에 적절한 도구를 활용하는 것이 필요하고, 스케쥴링된 태스크들은 가급적 팀 내에서 한 곳에서 관리될 수 있도록 하는 것이 좋다. 왜냐하면 스케쥴링 태스크가 산재되면 전체 로직을 파악하기 어렵고, 스케쥴링된 태스크들이 정상적으로 실행되고 있는지 알기 어렵기 때문이다.
'Spring' 카테고리의 다른 글
| [Log] 로그 관리, 로그 수집 및 로그 시각화 까지 로그 관리하는 방법 - 1 - (0) | 2025.06.22 |
|---|---|
| [스프링/JDBC Template] 스프링-디비1편 6-2. JDBC Template (0) | 2024.02.02 |
| [스프링/예외] 스프링-디비1 6-1. 스프링과 문제 해결 - 예외 처리, 반복 (0) | 2024.02.02 |
| [스프링/@Transactional] 4-2. 트랜잭션 AOP 이해 (0) | 2024.02.01 |
| [스프링/트랜잭션] 4-1. 스프링의 트랜잭션 (0) | 2024.02.01 |

