-JPA의 데이터 타입 분류
1. 엔티티 타입
@Entity로 정의하는 객체
데이터가 변해도 식별자로 지속해서 추적이 가능하다
예) 회원 엔티티의 키나 나이 값을 변경해도 식별자로 인식이 가능하다
엔티티 타입 특징
1) 식별자가 있다
2) 생명 주기를 관리한다
3) 공유할 수 있다
2. 값타입(기본값 타입, 임베디드 타입, 컬렉션 값 타입)
int,Integer,String처럼 단순히 값으로 사용하는 자바 기본 타입이나 객체를 말한다
식별자가 없고 값만 있으므로 변경시 추적이 불가능하다
예) 숫자 100을 200으로 변경하면 완전히 다른 값으로 대체하는 것이다
값 타입의 특징
1) 식별자가 없다
2) 생명주기를 엔티티에 의존한다
3) 공유하지 않는 것이 안전하다(복사해서 사용한다)
1)기본값 타입
자바 기본 타입(int,double)
래퍼(wrapper인가?) 클래스(Integer,Long)
String
생명주기를 엔티티에 의존한다(회원을 삭제하면 이름,나이 필드도 함께 삭제된다)
값 타입은 공우하면 안된다(회원 이름 변경시 다른 회원이 이름도 함게 변경되면 안되므로)
-자바의 기본 타입(int,double같은 primitive type)은 절대 공유하면 안된다!!
이유: 기본 타입은 항상 값을 복사한다. 그래서 복사된 값 중 하나가 변경되면 그것을 참조하는 다른 값들도 다 변경된다
Integer같은 래퍼 클래스나 String 같은 특수한 클래스는 공유가능한 객체이지만 변경하지 않는다
2)임베디드타입(embedded type, 복합 값 타입)
새로운 값 타입을 직접 정의할 수 있다.
JPA에서는 embedded type일고 한다.
주로 기본 값 타입을 모아서 만들기 때문에 복합 값 타입이라고도 한다
int,String(기본 값 타입)과 같은 값 타입이다
-회원엔티티가 모든 정보를 가지고 있어도 되지만,
startDate/endDate 필드는 Period 객체에
city/street/zipcode 필드는 Addres 객체에 넣어서 Member에서 연관관계를 형성할 수도 있다
-임베디드 타입 사용법
@Embeddable: 값 타입을 정의하는 곳에 표시
@Embedded: 값 타입을 사용하는 곳에 표시
기본 생성자는 필수다
-임베디드 타입의 장점
재사용이 가능하다
높은 응집도를 가진다
Period.isWork()처럼 해당 값 타입만 사용하는 의미있는 메소드를 만들 수 있다
임베디드 타입을 포함한 모든 값 타입은, 값 타입을 소유한 엔티티에 생명주기를 의존한다
-임베디드 타입과 테이블 매핑
임베디드 타입은 엔티티의 값일 뿐이다.
임베디드 타입을 사용하기 전과 후에 매핑하는 테이블은 같다
객체와 테이블을 아주 세밀하게(fine-grained) 매핑하는 것이 가능하다
잘 설계한 ORM 애플리케이션은 매핑한 테이블의 수보다 클래스의 수가 더 많다

-임베디드 타입과 연관관계

-@AttributeOverride: 속성 재정의
한 엔티티에서 같은 값 타입을 사용하면? 컬럼명이 중복된다
@AttributeOverride, @AttributeOverrides를 사용해서 컬럼명 속성을 재정의한다

-임베디드 타입의 값이 null이면 매핑한 컬럼 값은 모두 null이다
값 타입
값 타입은 객체 세상을 조금이라도 단순화하기 위해 만든 개념이므로 단순하고 안전하게 다룰 수 있어야 한다
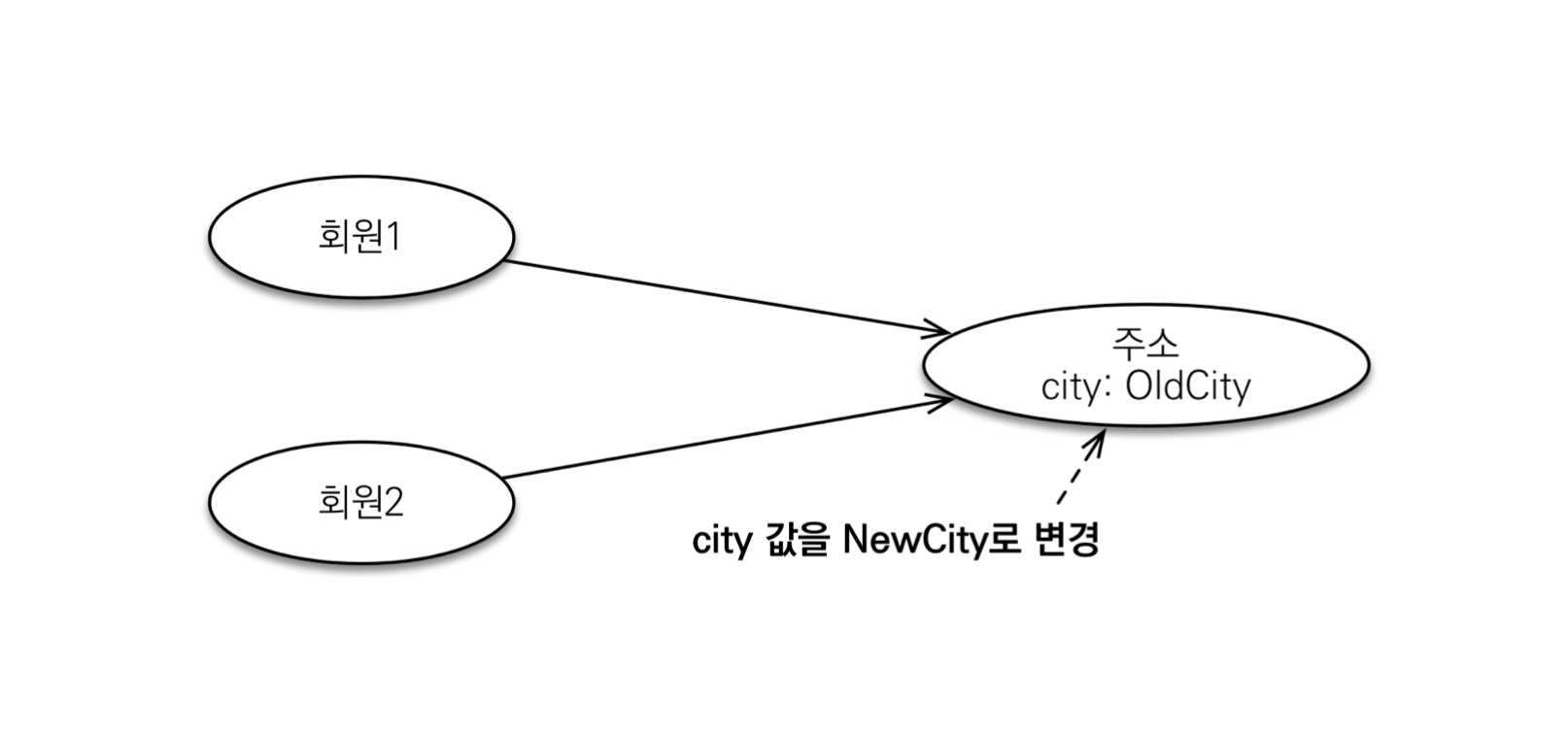
-값 타입 공유 참조
임베디드 타입 같은 값 타입을 여러 엔티티에서 공유하면 위험하다.
부작용이 발생한다
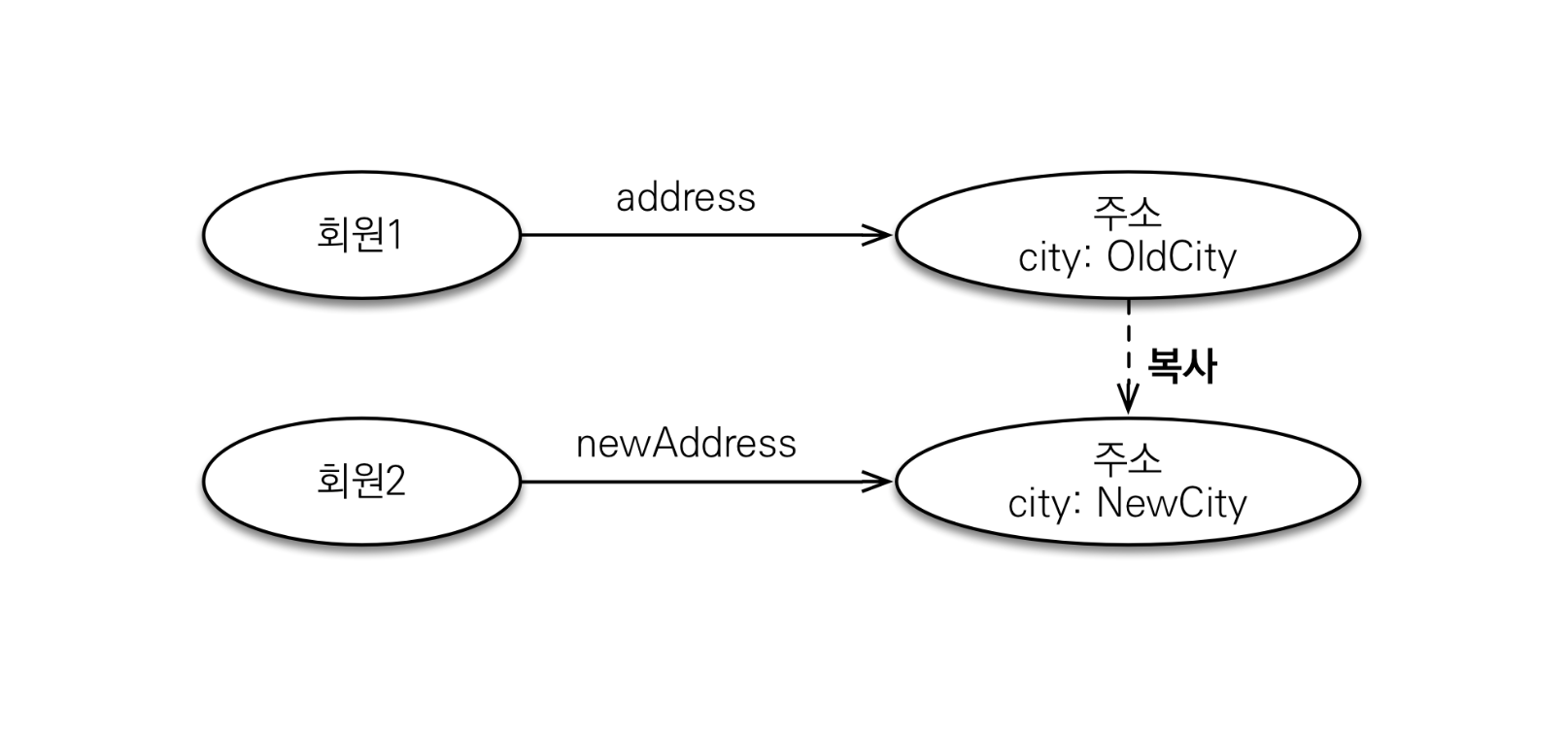
-값 타입 복사
값 타입의 실제 인스턴스인 값을 공유하는 것은 위험하다
대신 값(인스턴스)를 복사해서 사용한다
-객체 타입의 한계
항상 값을 복사해서 사용하면 공유 참조로 인해 발생하는 부작용을 피할 수 있다
문제는 임베디드 타입처럼 직접 정의한 값 타입은 자바의 기본 타입이 아니라 객체 타입이다
자바 기본 타입에 값을 대입하면 값을 복사하지만
객체 타입은 참조 값을 직접 대입하는 것을 막을 방법이 없다
객체의 공유 참조는 피할 수 없다
-불변 객체: 생성시점 이후 절대 값을 변경할 수 없는 객체
객체 타입을 수정할 수 없게 만들면 부작용을 원천 차단할 수 있다
갑 타입은 불변객체(immutable object)로 설계해야한다
생성자로만 값을 설정하고 수정자(setter)를 만들지 않으면 된다
참고: Integer,String은 자바가 제공하는 대표적인 불변 객체이다
===> 불변이라는 작은 제약으로 부작용이라는 큰 재앙을 막을 수 있다
-값 타입 비교: 인스턴스가 달라도 그 안에 값이 같으면 같은 것으로 봐야한다
1)동일성(identity) 비교: 인스턴스의 참조 값을 비교하고 == 사용한다
2)동등성(equivalence) 비교: 인스턴스의 값을 비교, equals()를 사용한다
*값 타입은 a.equals(b)를 사용해서 동등성 비교를 해야한다*
값타입의 equals() 메소드를 적절하게 재정의한다(주로 모든 필드에서 사용한다?)
3)컬렉션 값 타입(collection value type)

-값 타입 컬렉션이란
값 타입을 하나 이상 저장할 때 사용한다
@ElementCollection, @Collection Table 어노테이션을 사용한다
데이터베이스는 컬렉션을 같은 테이블에 저장할 수 없으므로 컬렉션을 저장하기 위한 별도의 테이블이 필요하다
참고: 값 타입 컬렉션은 영속성(cascade) 전에 고아 객체 제거 기능을 필수로 가진다고 볼 수 있다
-실습 코드
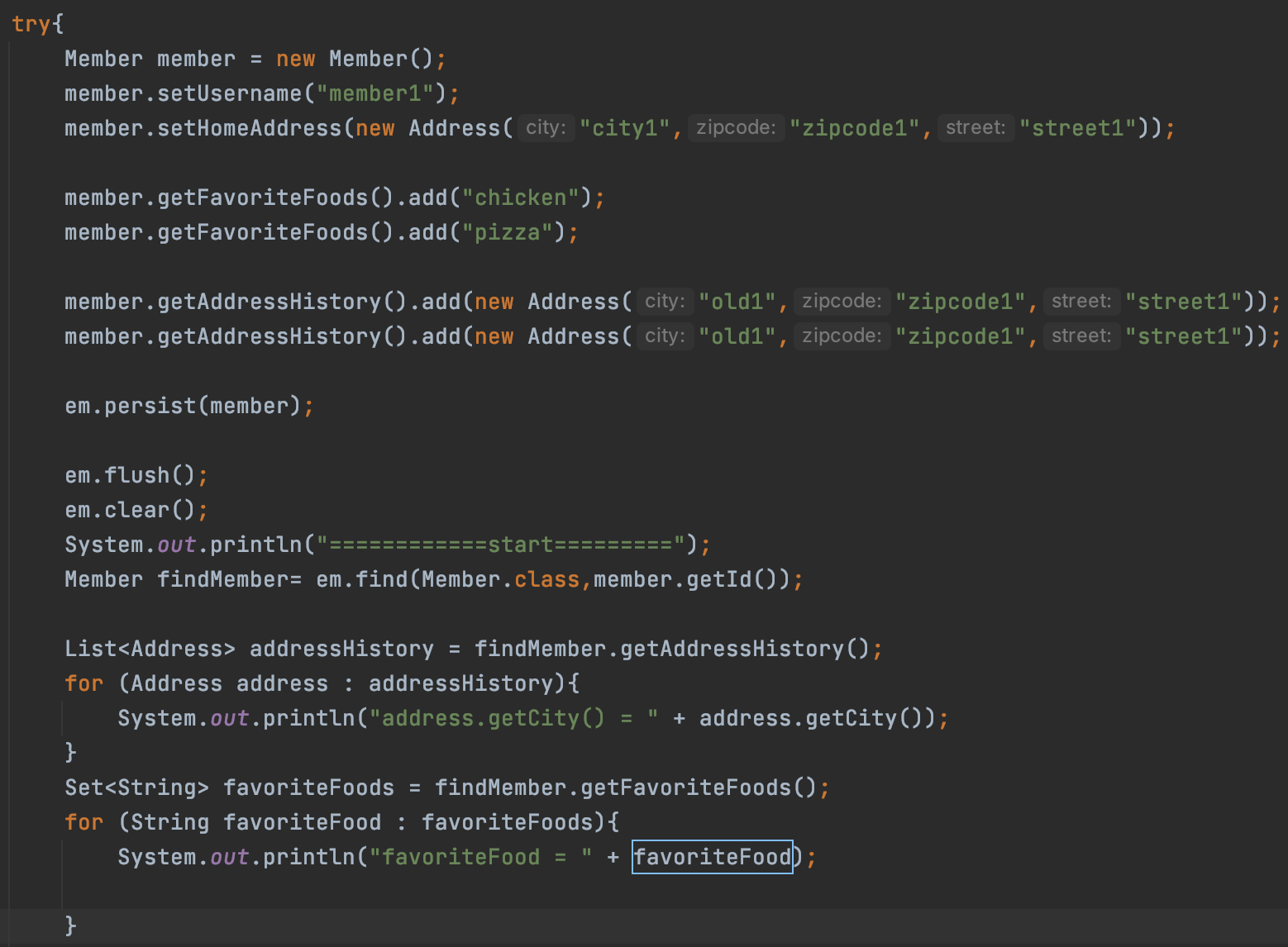
-값 타입 컬렉션의 제약사항
값 타입은 엔티티와 다르게 식별자 개념이 없다
값은 변경하면 추적이 어렵다
값 타입 컬렉션에 변경 사항이 발생하면, 주인 엔티티와 연관된 모든 데이터를 삭제하고,
값 타입 컬렉션에 있는 현재 값을 모두 다시 저장한다(값타입 컬렉션 변경 발생 -> 값 타입 컬렉션 모두 삭제 -> 값 타입 컬렉션에 있는 현재 값을 모두 다시 저장)
값 타입 컬렉션을 매핑하는 테이블은 모든 컬럼을 묶어서 기본키를 구성해야한다. null 입력x, 중복저장 x
-값 타입 컬렉션 대안-> 여기 실습 코드 보면서 공부 해야할 것 같음
실무에서는 상황에 따라 값 타입 컬렉션 대신에 일대다 관계를 고려한다
일대다 관계를 위한 엔티티를 만들고, 여기에서 값 타입을 사용한다
영속성 전이(cascade)+고아 객체 제거를 사용해서 값 타입 컬렉션처럼 사용한다
예시) Address Entity
=====> 값 타입은 정말 값 타입이라 판단될 때만 사용한다
엔티티와 값 타입을 혼동해서 엔티티를 값 타입으로 만들면 안됨
식별자가 필요하고, 지속해서 값을 추적, 변경해야 한다면 그것은 값 타입이 아닌 엔티티다