공부한 날짜: 2021. 11. 04
-신장트리(Spanning Tree): 그래프의 모든 정점을 연결하는 트리
-최소 신장 트리, 최소 가중치 신장트리: 각 간선이 갖고 있는 가중치의 합이 최소가 되는 신장 트리
*최소 신장트리는 각 구성 요소가 서로 연결되어 있고 간선에 가중치가 실려있는 연결된 가중치 그래프로부터 만들어짐
최소 신장트리를 만드는 알고리즘: 프림 알고리즘(Prim's algorithm), 크루스칼 알고리즘(Kruskal's algorithm)
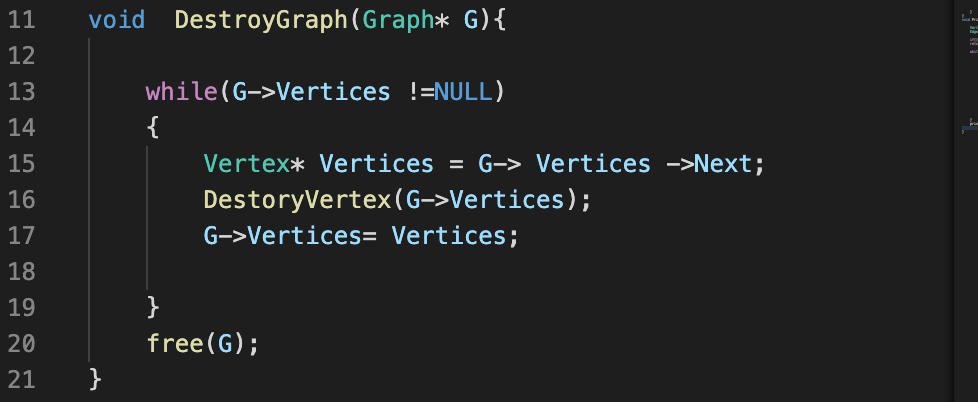
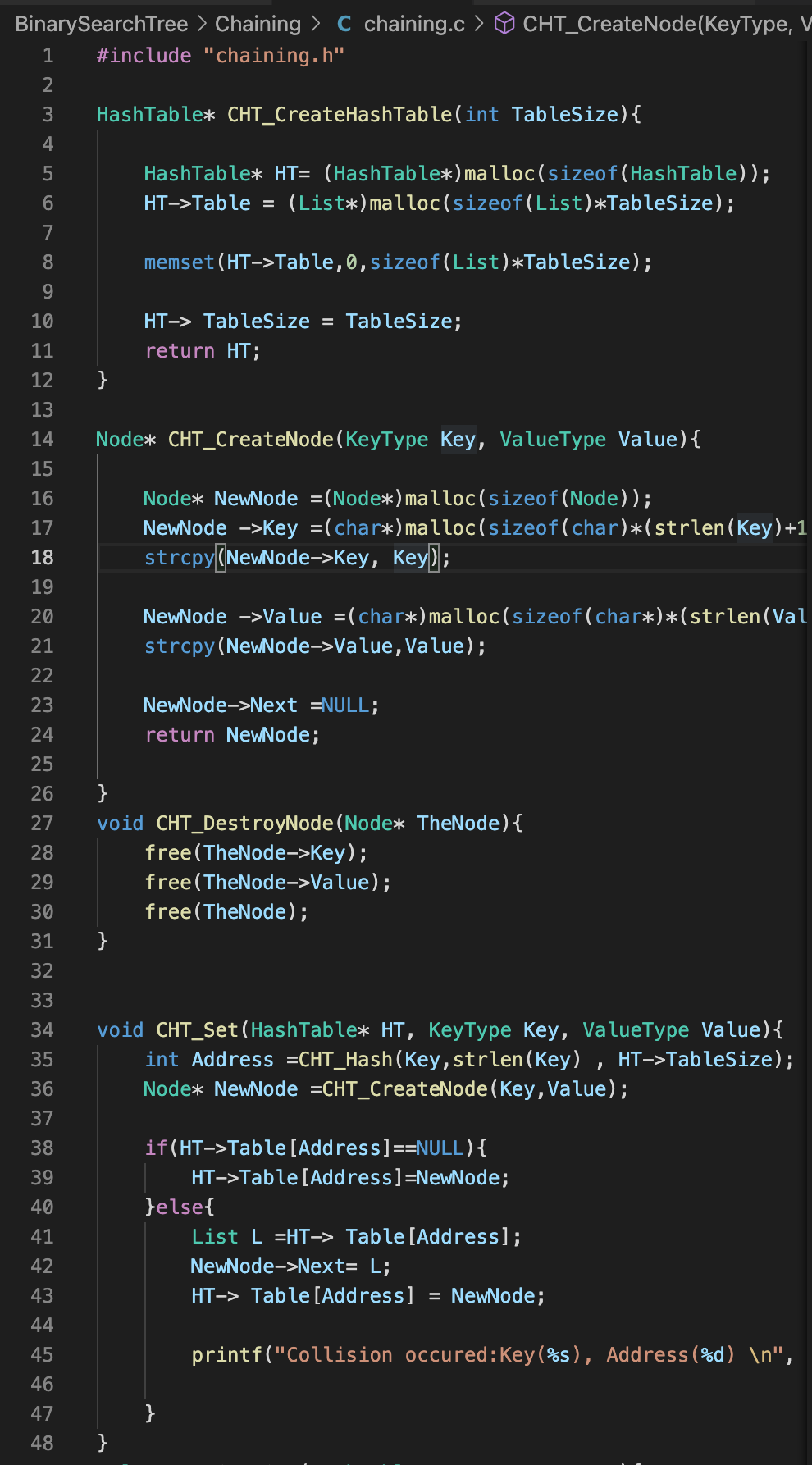
* 구현부분에 어려운 부분이 있어서 여러번 보면서 이해해야할 것 같음
1. 프림 알고리즘(Prim's algorithm)
- 과정
ㄱ. 그래프와 최소 신장 트리를 준비
ㄴ. 그래프에서 임의의 정점을 시작 정점으로 선택하여 최소 신장트리의 루트노드로 삽입
ㄷ. 최소 신장 트리에 삽입되어 있는 정점들과 이 정점들의 모든 인접 정점 사이에 있는 간선의 가중치 조사. 간선 중에 가장 가중치가 작은 것을 골라 이 간선에 연결되어 있는 인접 정점을 최소 신장 트리에 삽입. 단, 새로 삽입되는 정점은 최소 신장 트리에 삽입되어 있는 기존의 노드들과 사이클을 형성해서는 안됨
ㄹ. ㄷ.의 과정 바복하다 최소 신장 트리가 그래프의 모든 정점을 연결하게 되면 알고리즘 종료
- 프림 알고리즘의 문제
(1) 최소 신장 트리의 자료구조(배열,링크드리스트,트리)로 무엇을 사용할 것인가?
: 이 책에서는 그래프를 사용
(2)조사 대상 간선에서 최소 가중치를 가진 간선을 골라는 과정에서 성능저하
: 정점 하나를 추가할 때마다 최소 가중치를 찾기 위해 그래프 내의 정점 n개를 순회해야하므로, n^2만큼의 탐색을 해야함
이걸 해결하기 위해 삽입 삭제가 빠르고, 최소 값을 찾는데에 거의 비용이 들지 않는 우선순위 큐를 이용함
2. 크루스칼 알고리즘(Kruskal's algorithm)
: 그래프 내의 모든 간선들의 가중치 정보를 사전에 파악하고, 이 정보를 토대로 최소 신장 트리를 구축해나가는 알고리즘
- 과정
ㄱ. 그래프 내의 모든 간선을 가중치의 오름차순으로 목록을 만듦
ㄴ. ㄱ.에서 만든 간선의 목록을 차례대로 순회하면서 간선을 최소 신장트리에 추가함. 단, 이때 추가된 간선으로 인해 최소 신장 트리 내에 사이클이 형성 되면 안됨
- 크루스칼 알고리즘의 문제
: 최소 신장 트리에 생기는 사이클을 어떻게 효율적으로 감지할 것인가-> 깊이 우선 탐색 / 분리집합 -> 분리집합으로 진행 -> 모든 간선들을 가중치의 오름차순으로 정렬 -> 각 정점 별로 분리 집합 만듦 -> 알고리즘 진행순서대로 진행
-크루스칼 구현


(1) 깊이 우선 탐색 이용시
: 하나의 정점을 기준으로 탐색을 실행하고, 방문한 정점을 visited로 표시한뒤 해당 정점에서 실행한 깊이 우선 탐색 시 visted를 만나면 그 정점들은 사이클을 형성한다는 걸 알 수 있음
단점으로는 탐색 비용이 큰 것
(2) 분리 집합 이용
: 간선으로 연결되어 있는 정점들에 대해서는 합집합 수행. 간선으로 이어야할 두 정점이 같은 집합에 속해 있다면 그 정점들이 사이클을 생성한다는 걸 알 수 있다.
'알고리즘 &자료구조' 카테고리의 다른 글
| [알고리즘 ] 16. 문자열 검색 (0) | 2021.11.04 |
|---|---|
| [알고리즘] 15. 최단 경로 탐색 (0) | 2021.11.04 |
| [알고리즘] 13. 위상 정렬 (0) | 2021.11.04 |
| [알고리즘] 12. 그래프 (0) | 2021.11.02 |
| [알고리즘] 11. 해시 테이블(Hash Table) (0) | 2021.10.28 |