공부한 날짜: 2021. 10. 26
-힙: 힙 순서 속성(Heap Order Property)을 만족하는 완전 이진 트리
-완전 이진 트리: 최고 깊이를 제외한 모든 기이의 노드들이 완전히 채워져 있는 이진트리
-힙 순서 속성: 트리 내의 모든 노드가 부모 노드보다 커야한다는 규칙
-힙이 보장하는 한가지 특성: '힙에서 가장 작은 데이터를 갖는 노드는 루트 노드이다.'
-삽입 연산
1. 힙 최고 깊이 최 우측에 노드 추가. 이때 힙은 완전 이진트리 유지
2. 부모노드와 비교해서 크면 멈추고, 작으면 다음 단계
3. 부모노드와 삽입 노드 바꾸고, 2번 진행
핵심은 새로 추가한 노드가 힙 순서 속성을 만족시킬 때따깆 부모노드와 계속해서 교환해 나가는 것
-삭제 연산(여기서는 힙의 최소값, 루트노드 삭제)
여기서도 노드 삭제 후 뒤처리가 주요 내용
*뒤처리 과정
1. 힙의 루트에 최고 깊이, 최 우측에 있던 노드를루트 노드로 옮겨온다.
2. 옮겨온 노드의 양쪽 자식을 비교하여 작은쪽 자식과 위치 교환
3. 힙 순서 속성 만족하면 멈추고, 아니면 2번부터 반복한다
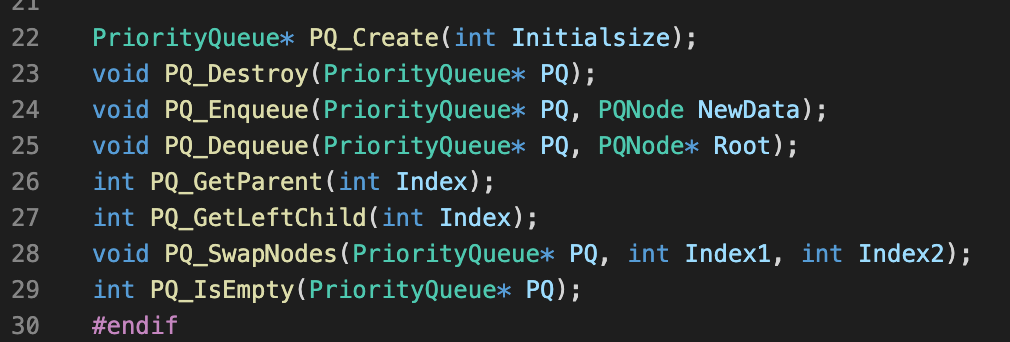
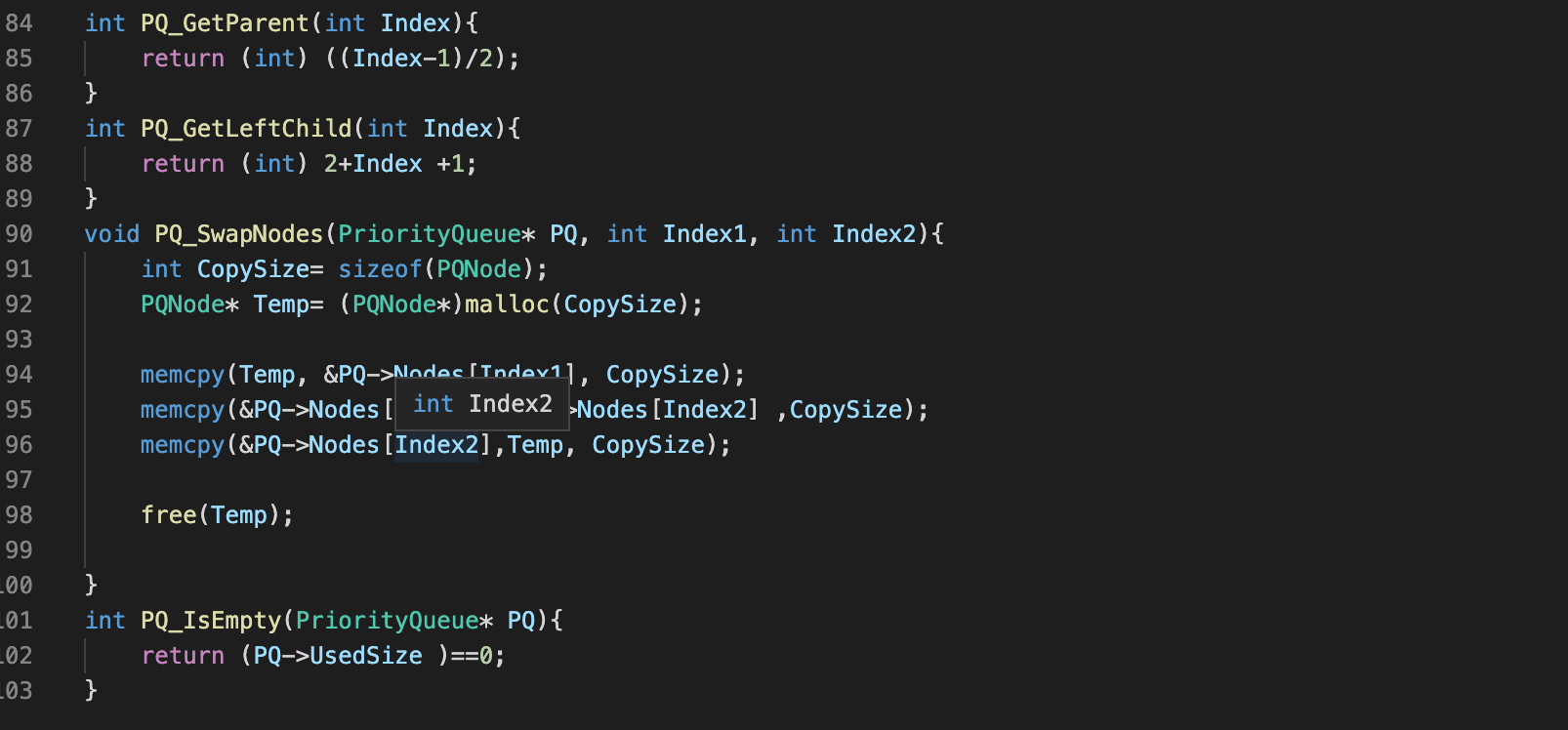
-힙의 구현
힙에 사용하는 자료구조로는 배열이 더 낫다고 함
완전 이진 트리를 배열로 나타내는 방법: 깊이 n의 노드는 배열의 (2^n -1) ~ 2*(2^n -1)번 요소에 저장한다
이 배열의 장점: 배열 인덱스 만으로 힙의 각 노드 위치, 부모/자식 관계를 한번에 알아낼 수 있다
* k번 인덱스에 위치한 노드의 양쪽 자식 노드들이 위치한 인덱스
왼쪽 자식 노드: 2k+1, 오른쪽 자식 노드 2k+2
*k번 인덱스에 위치한 노드의 부모 노드가 위치한 인덱스: (k-1)/2의 몫








'알고리즘 &자료구조' 카테고리의 다른 글
| [알고리즘] 12. 그래프 (0) | 2021.11.02 |
|---|---|
| [알고리즘] 11. 해시 테이블(Hash Table) (0) | 2021.10.28 |
| [알고리즘] 9. 우선순위 큐(Priority Queue) (0) | 2021.10.26 |
| [알고리즘] 7. 이진 탐색 트리 (0) | 2021.10.23 |
| [알고리즘] 6. 이진탐색 (0) | 2021.10.23 |